
Aug 01, 2024
SupportLogic Acquires xFind and its Precision Answer Engine to Set a New Standard for Support Experience
Read More


Sariel Moshe
Sariel Moshe, Co-Founder and CPO, xFindComing from a background in threat intelligence and cybersecurity, particularly in the pre-LLM (Large Language Models) era, our mission at xFind was to create a solution that could offer knowledge workers more precise insights at a faster pace than the keyword-based searches that were prevalent at the time.
As we delved deeper, it became apparent that the function with the greatest need for real-time insight retrieval and knowledge creation was enterprise customer support. Customer support has always been, and continues to be, a crucial knowledge engine for companies. The individuals handling support calls are the front-line experts who understand the customer’s challenges and the necessary solutions.
Despite the existence of methodologies like Knowledge-Centered Service (KCS), the journey to harness the full potential of this knowledge engine was hindered by the complex technical challenges and the unique nature of enterprise knowledge. Additionally, outdated process management practices often stifled the ability to fully leverage this potential.
Our main insight, which required the most effort to crack, was “how can we provide support agents with the relevant knowledge they need in real time and remove the effort involved in searching for the information required to piece it together?” We understood this to be the biggest roadblock, and one that existing search solutions had not overcome.
We called this concept “Implicit Search” – running a query based on the context of a support ticket without requiring any explicit query from the user. The complexity involved in solving this was twofold: first we had to be able to run a query that consists of an entire support case, which could be thousands of words long; second, we needed to be able to assess what specific information items are relevant, as well as if there were any relevant information available at all.
Having built this solution before GenAI became so available, it enabled us to adapt quickly to the new reality of RAG. We now have the ultimate RAG engine in our hands, one that can handle any natural language question, and can present to a large language model (LLM) the precise context with which to develop an answer to that question.
From many conversations I’ve had over the past year, I’ve come to realize that most people who want to implement an AI based question answering solution don’t understand how complex a technology it is, and the many pitfalls involved in developing it.
The main challenges have to do with the following:
Benchmarking results versus OpenAI in March 2024:
| Data type | Collection | Success@5 ADA-2.0 | Success@5 SupportLogic | Failure@5 ADA-2.0 | Failure@5 SupportLogic | No. of Queries | No. of Documents |
|---|---|---|---|---|---|---|---|
| Public | Ember | 91% | 96% | 9% | 4% | 102 | 123 |
| Slightly technical | Owllabs | 91% | 94% | 9% | 6% | 250 | 694 |
| Technical | 8X8 | 75% | 86% | 25% | 14% | 250 | 3,227 |
| Domain specific | Waters | 78% | 87% | 22% | 13% | 400 | 13,504 |
Let’s focus this all down to one point: The concept of Retrieval Augmented Generation (RAG) as a reliable, enterprise-ready solution, mainly depends on the quality of the Search Engine it runs, not on the power of the LLM it employs.
As seen in the flowchart below, xFind is a market leader in the technology required to consistently manage these challenges at scale, and enables a true enterprise-grade question-answering experience for complex data environments.
This technology includes:
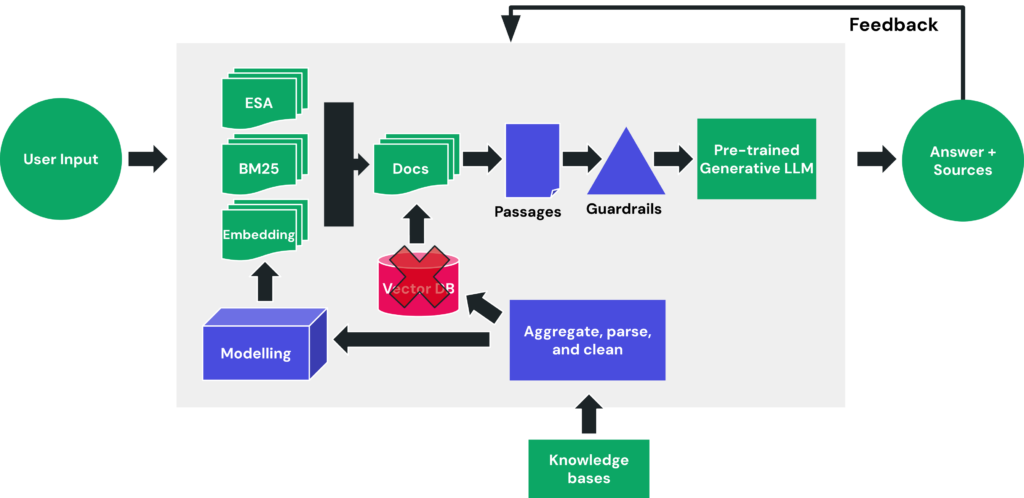
After five years of hard work developing these capabilities, and adapting them to the realities of the B2B Customer Support market, we find ourselves at a pivotal moment with xFind joining forces with SupportLogic. The advancements in computational power, AI, and LLMs have brought us closer than ever to realizing our vision.
SupportLogic has developed an incredibly robust suite of solutions aimed at making the support workflow smarter and more efficient. These solutions are being used by leading enterprise support organizations who realize significant value in terms of improved customer experience and operational efficiency. This foundation sets the stage for the next natural step: integrating knowledge creation and access seamlessly into the support process.
With this integration, we are not just enhancing support workflows; we are transforming customer support teams into the ultimate knowledge teams. These teams, armed with real-time insights and advanced knowledge creation tools, can provide unparalleled support and drive continuous improvement across the enterprise.
The support industry has always been the unsung hero of enterprise operations, silently driving customer satisfaction and business success. With our combined efforts, we aim to bring this vital function into the spotlight, showcasing its true potential and transforming it into a strategic asset.
Want the latest B2B Support, AI and ML blogs delivered straight to your inbox?


")